![]() In dieser Lösungsbeschreibung wird erläutert, wie die integrierte Hardware- und Softwarelösung von Napatech NVMe/TCP-Speicher-Workloads von der Host-CPU auf eine IPU auslagert, was CAPEX, OPEX und den Energieverbrauch deutlich reduziert. Außerdem wird Sicherheitsisolierung in das System eingeführt, was den Schutz vor Cyber-Angriffen erhöht.
In dieser Lösungsbeschreibung wird erläutert, wie die integrierte Hardware- und Softwarelösung von Napatech NVMe/TCP-Speicher-Workloads von der Host-CPU auf eine IPU auslagert, was CAPEX, OPEX und den Energieverbrauch deutlich reduziert. Außerdem wird Sicherheitsisolierung in das System eingeführt, was den Schutz vor Cyber-Angriffen erhöht.
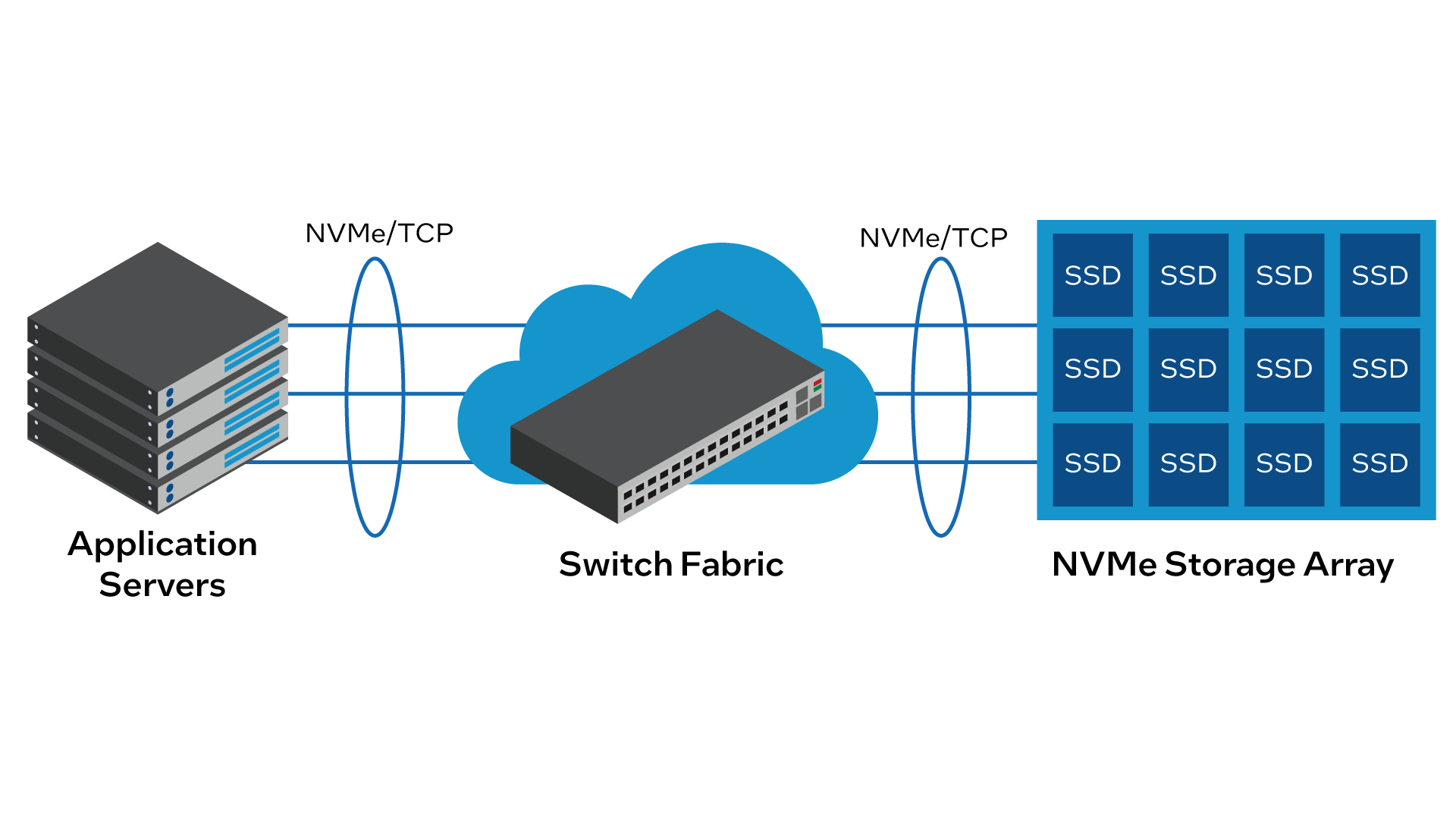
Was ist NVMe over TCP?
NVMe/TCP ist eine Speichertechnik, die über Standard-Rechenzentrums-Fabrics Zugriff auf Non-Volatile Memory Express (NVMe)-basierte Speichergeräte ermöglicht. Siehe Abbildung 1.
Moderne Cloud- und Enterprise-Rechenzentren verwenden zunehmend NVMe/TCP, da es gegenüber älteren Speicherprotokollen wie Internet Small Computer System Interface (iSCSI) oder Fibre Channel überzeugende Vorteile bietet:
-
Höhere Leistung: NVMe wurde entwickelt, um alle Vorteile von modernen Highspeed-NAND-basierten Solid-State-Drives (SSDs) zu nutzen, und bietet deutlich höhere Datenübertragungsraten als herkömmliche Speicherprotokolle. NVMe/TCP erweitert diese Vorteile auf vernetzte Speicherumgebungen und ermöglicht Rechenzentren über die Fabric leistungsstarken Speicherzugriff.
-
Reduzierte Latenz: Die latenzarme Natur von NVMe/TCP ist entscheidend für datenintensive Anwendungen und Echtzeit-Workloads. NVMe/TCP kann dazu beitragen, Latenzzeiten bei Speicherzugriff zu verringern und die Gesamtleistung von Anwendungen zu verbessern, indem der Kommunikationsaufwand minimiert wird und Protokollkonvertierungen überflüssig werden.
-
Skalierbarkeit: Oft müssen Rechenzentren mit großen Speicherumgebungen umgehen. NVMe/TCP sorgt durch eine flexible und effiziente Speicherzugriffslösung über ein Netzwerk für nahtlose Skalierbarkeit. Bei steigender Anzahl von NVMe-Geräten können Rechenzentren ein hohes Leistungsniveau ohne signifikante Engpässe gewährleisten.
-
Gemeinsam genutzte Speicherpools: NVMe/TCP ermöglicht die Einrichtung von gemeinsam genutzten Speicherpools, auf die verschiedene Server und Anwendungen gleichzeitig zugreifen können. Diese gemeinsam genutzte Speicherarchitektur verbessert die Ressourcenauslastung und vereinfacht die Speicherverwaltung, was zu deutlichen Kosteneinsparungen führt.
-
Kompatibilität mit älterer Infrastruktur: Rechenzentren verfügen meist über eine vorhandene Infrastruktur, die auf Ethernet-, InfiniBand- oder Fibre-Channel-Netzwerken basiert. NVMe/TCP ermöglicht es Unternehmen, vorhandene Fabric-Investitionen weiterzunutzen und gleichzeitig neuere, NVMe-basierte Speichertechnik zu integrieren, ohne die gesamte Netzwerkinfrastruktur austauschen zu müssen.
-
Effiziente Ressourcenauslastung: NVMe/TCP ermöglicht eine bessere Ressourcenauslastung, da der Bedarf nach dedizierten Speicherressourcen auf jedem Server reduziert wird. Verschiedene Server können über das Netzwerk auf gemeinsam genutzte NVMe-Speichergeräte zugreifen, was die Auslastung teurer NVMe-Speicherressourcen optimiert.
-
Zukunftssicherheit: Mit der Weiterentwicklung und dem Einsatz schnellerer Speichertechnologien in Rechenzentren bietet NVMe/TCP einen zukunftsorientierten Ansatz für Speicherzugriff, der sicherstellt, dass Speichernetzwerke den steigenden Anforderungen moderner Anwendungen und Workloads gerecht werden können.
Insgesamt ist NVMe/TCP eine leistungsstarke und flexible Speicherlösung für Rechenzentren, die in gemeinsam genutzten und skalierbaren Speicherumgebungen für hohe Leistung, geringe Latenz und effiziente Ressourcenauslastung sorgt.
Begrenzungen von rein softwarebasierten Speicherarchitekturen
Trotz der überzeugenden Vorteile von NVMe/TCP für Speicher müssen sich Betreiber von Rechenzentren der erheblichen Einschränkungen bewusst sein, die mit einer Implementierung verbunden sind, bei der alle erforderlichen Speicher-Initiator-Dienste auf der Host-Server-CPU in Software ausgeführt werden. Siehe Abbildung 2.
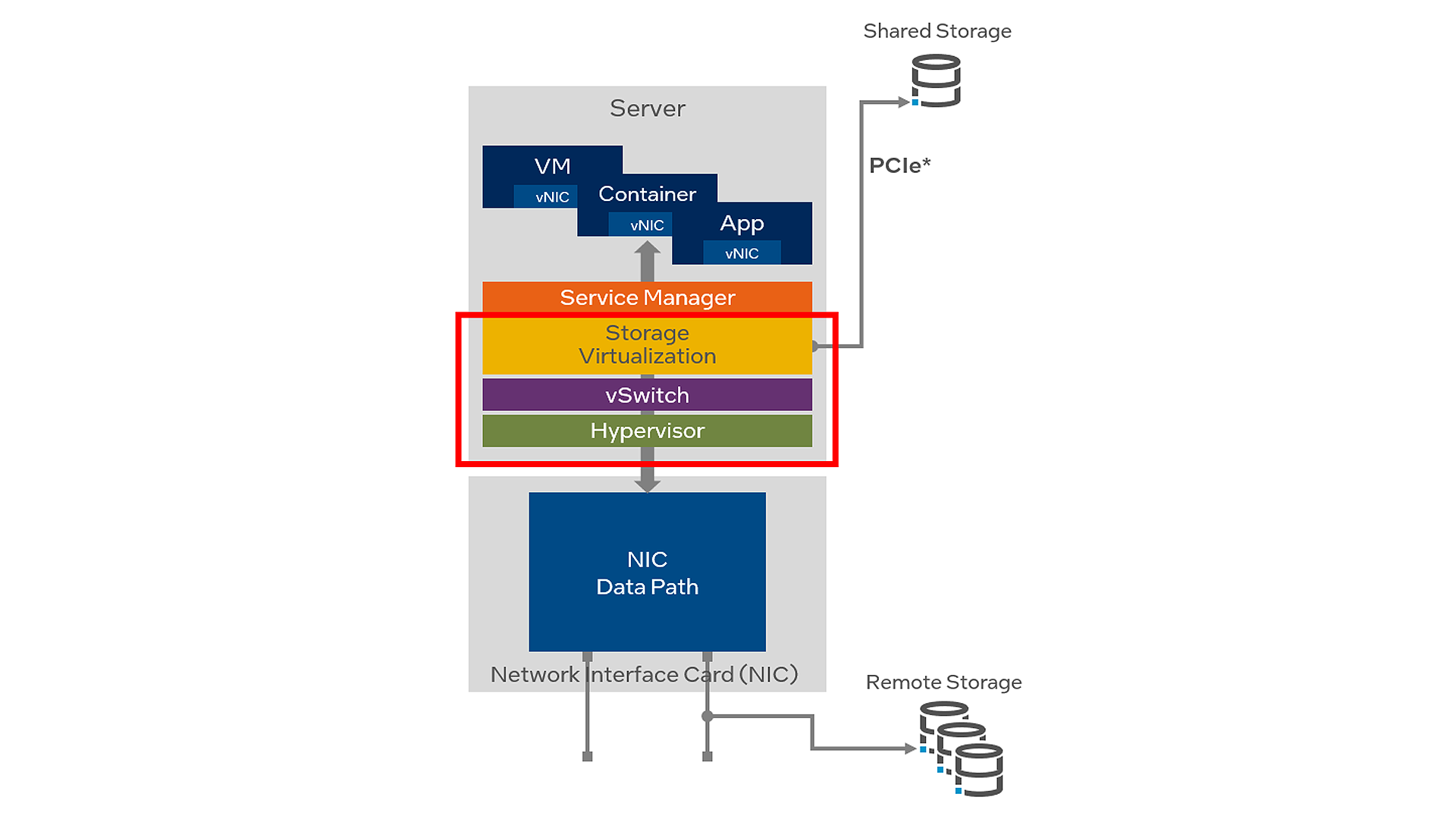
Erstens entsteht ein Sicherheitsrisiko auf der Systemebene, wenn die Speicher-Virtualisierungssoftware, der Hypervisor oder der virtuelle Switch (vSwitch) bei einem Cyber-Angriff kompromittiert werden.
Zweitens gibt es keine Möglichkeit, eine vollständige Isolierung zwischen Mandanten-Workloads zu gewährleisten. Eine einzelne Architektur beherbergt Anwendungen und Daten verschiedener Kunden in einer Multi-Tenant-Umgebung. Der „Noisy Neighbor“-Effekt tritt auf, wenn eine Anwendung oder virtuelle Maschine (VM) die meisten der verfügbaren Ressourcen nutzt und die Systemleistung für andere Mandanten in der gemeinsam genutzten Infrastruktur beeinträchtigt.
Schließlich wird ein erheblicher Teil der Host-CPU-Kerne für den Betrieb von Infrastrukturdiensten wie Speicher-Virtualisierungssoftware, Hypervisor und vSwitch benötigt. Das verringert die Anzahl der CPU-Kerne, die für VMs, Container und Anwendungen monetarisiert werden können. Studien zeigen, dass in der Regel zwischen 30 % und 50 % der CPU-Ressourcen in Rechenzentren von Infrastrukturdiensten genutzt werden.
In einem leistungsstarken Speicher-Subsystem muss die Host-CPU ggf. verschiedene Protokolle wie Transmission Control Protocol (TCP), Remote Direct Memory Access over Converged Ethernet (RoCEv2), InfiniBand und Fibre Channel ausführen. Wenn die Host-CPU für die Ausführung dieser Speicherprotokolle und anderer Infrastrukturdienste stark ausgelastet ist, sinkt die Zahl der CPU-Kerne, die für Mandantenanwendungen verfügbar sind, deutlich. So kann eine 16-Kern-CPU ggf. nur die Leistung einer 10-Kern-CPU bieten.
Aus diesen und weiteren Gründen bringt eine rein softwarebasierte Architektur erhebliche geschäftliche und technische Herausforderungen für Speicher in Rechenzentren mit sich.
IPU-basierte Speicherauslagerungslösung
Das Auslagern der NVMe/TCP-Workload auf eine IPU in Kombination mit anderen Infrastrukturdiensten wie Hypervisor und vSwitch (siehe Abbildung 3.) eliminiert die Begrenzungen einer reinen Software-Implementierung und bietet Betreibern von Rechenzentren erhebliche Vorteile:
-
CPU-Auslastung: Die NVMe/TCP-Kommunikation umfasst die Kapselung von NVMe-Befehlen und Daten im TCP-Transportprotokoll. Die Host-CPU verarbeitet die Kapselungs- und Entkapselungsaufgaben, ohne sie auszulagern. Bei einer Auslagerung dieser Operationen auf dedizierte Hardware kann sich die CPU auf andere wichtige Aufgaben konzentrieren, was die Gesamtsystemleistung und CPU-Auslastung spürbar verbessert.
-
Geringere Latenz: Das Auslagern von NVMe/TCP-Kommunikationsaufgaben auf spezialisierte Hardware kann die Latenz bei der Verarbeitung von Speicherbefehlen deutlich reduzieren. So können Anwendungen beim Zugriff auf Remote-NVMe-Speichergeräte von kürzeren Antwortzeiten und mehr Leistung profitieren.
-
Effiziente Datenbewegung: Das Auslagern von Nicht-CPU-Anwendungsaufgaben auf separate Hardware-Beschleuniger ermöglicht eine effizientere Ausführung von Datenbewegungsoperationen als bei einer Allzweck-CPU. So lassen sich große Datenübertragungen und die Pufferverwaltung effektiv bewältigen, was geringere Latenzzeiten und einen höheren Gesamtdurchsatz mit sich bringt.
-
Verbesserte Skalierbarkeit: Das Auslagern von NVMe/TCP-Aufgaben verbessert in großen Speicherumgebungen die Skalierbarkeit. Da die CPU von der Netzwerkkommunikation entlastet wird, kann das System mehr gleichzeitige Verbindungen und Speichergeräte unterstützen, ohne CPU-gebunden zu werden.
-
Energieeffizienz: Durch das Auslagern bestimmter Aufgaben auf dedizierte Hardware kann der Energieverbrauch der Host-CPU reduziert werden. Diese Energieeffizienz kann in großen Rechenzentrumsumgebungen, in denen der Energieverbrauch eine wichtige Rolle spielt, einen signifikanten Beitrag leisten.
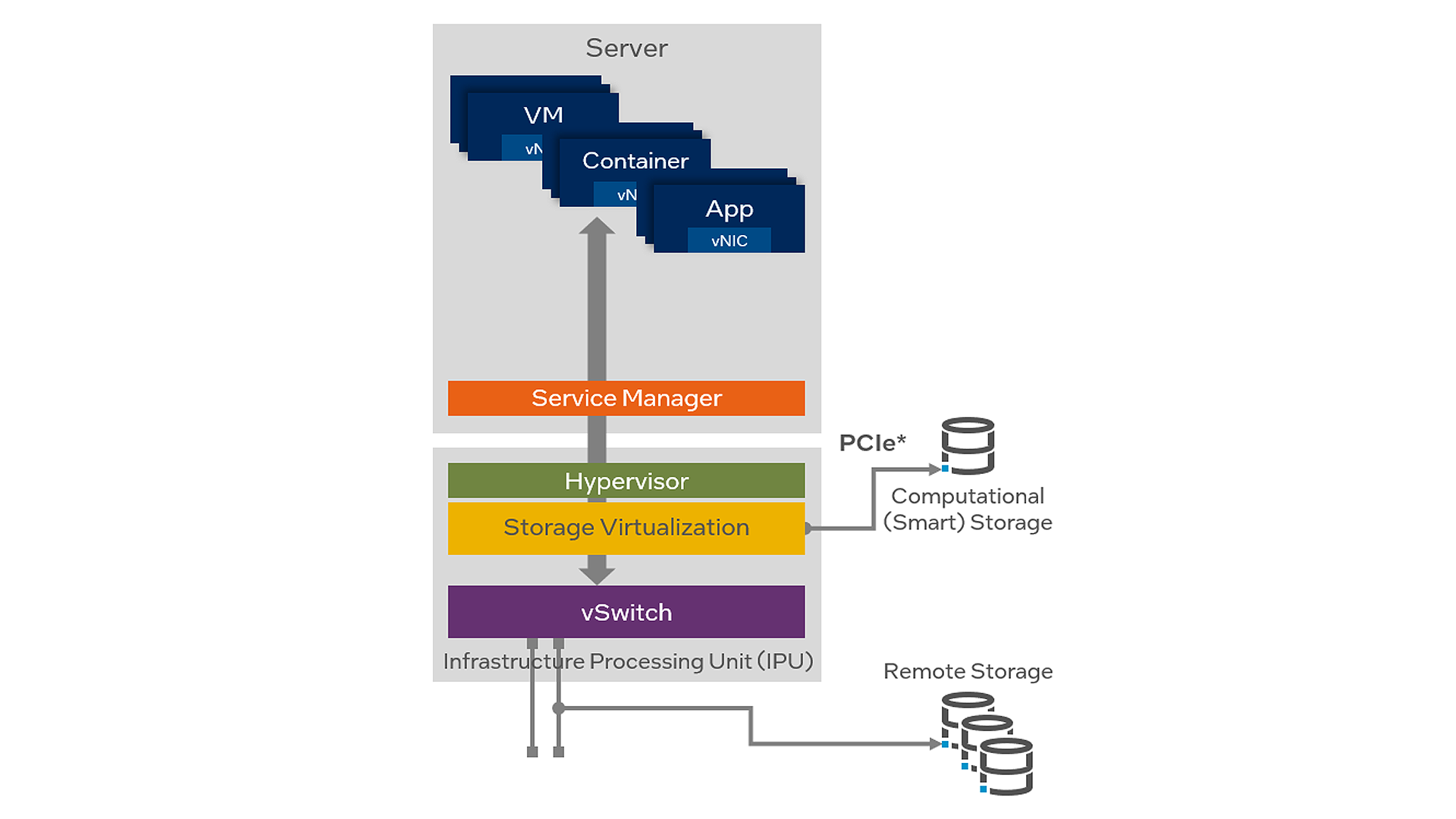
Neben den oben genannten Vorteilen, die für die NVMe/TCP-Speicher-Workload gelten, bietet eine IPU-basierte Systemarchitektur Optionen zur inkrementellen Sicherheitsisolierung, wodurch Infrastrukturdienste von Mandantenanwendungen isoliert werden. Dadurch wird gewährleistet, dass Speicher-, Hypervisor- und vSwitch-Dienste nicht durch einen von einer Mandantenanwendung ausgehendem Cyber-Angriff kompromittiert werden können. Die Infrastrukturdienste selbst bleiben geschützt, da der Bootprozess der IPU selbst sicher ist, während die IPU dann als Vertrauensanker für den Host-Server fungiert.
Integrierte Hardware- und Softwarelösung von Napatech
Napatech bietet eine integrierte Lösung auf der Systemebene für das Auslagern von Speicher in Rechenzentren, die den leistungsstarken Link-Storage-Software-Stack umfasst, der auf der F2070X IPU ausgeführt wird. Siehe Abbildung 4.
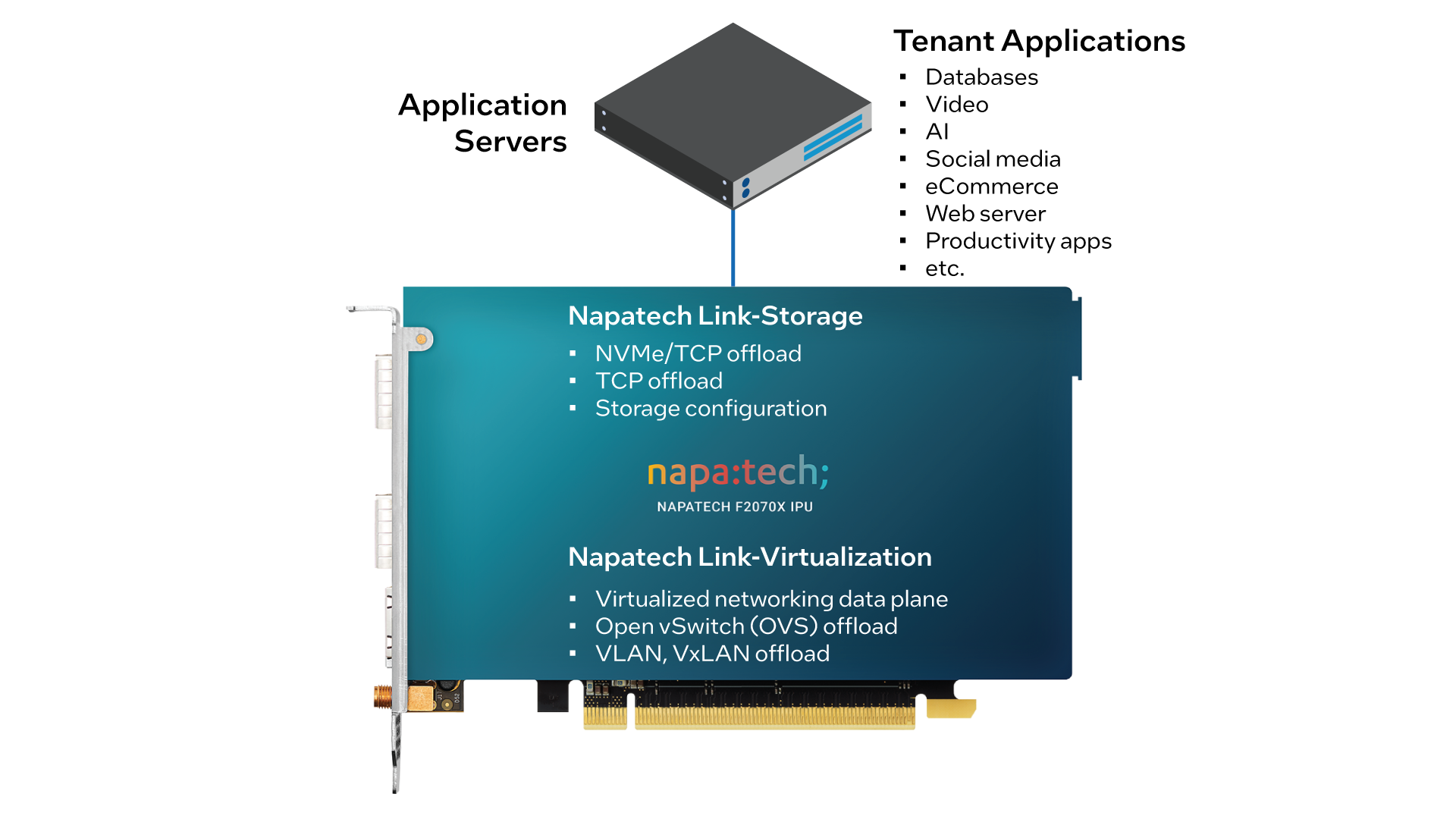
Die Link-Storage-Software enthält eine Vielzahl von Funktionen, darunter:
-
vollständige Auslagerung von NVMe/TCP-Workloads vom Host auf die IPU;
-
vollständige Auslagerung von TCP-Workloads vom Host auf die IPU;
-
NVMe-to-TCP-Initiator;
-
Speicherkonfiguration über die Storage Performance Development Kit Remote Procedure Call (SPDK RPC)-Schnittstelle;
-
Unterstützung von Multipath-NVMe;
-
Präsentation von 16 Blockgeräten an den Host über die virtio-blk-Schnittstelle;
-
Kompatibilität mit Standard-virtio-blk-Treibern in gängigen Linux*-Distributionen;
-
Sicherheitsisolierung zwischen der Host-CPU und der IPU, wobei es keine Netzwerkschnittstellen gibt, die dem Host zugänglich sind.
Neben Link-Storage unterstützt die F2070X auch die Link-Virtualization-Software, die eine ausgelagerte und beschleunigte virtualisierte Datenebene bietet, einschließlich Funktionen wie Open vSwitch (OVS), Live-Migration, VM-zu-VM-Spiegelung, VLAN/VxLAN-Kapselung/-Entkapselung, Q-in-Q, Lastausgleich mit Receive Side Scaling (RSS), Link-Aggregation und Quality of Service (QoS).
Da die F2070X auf einem FPGA und einer CPU anstatt auf ASICs basiert, kann die gesamte Funktionalität der Plattform nach der Bereitstellung aktualisiert werden. Egal ob Sie einen vorhandenen Dienst ändern, neue Funktionen hinzufügen oder bestimmte Leistungsparameter feinjustieren möchten: Die Neuprogrammierung kann in der vorhandenen Serverumgebung als reines Software-Upgrade durchgeführt werden, ohne dass Hardware getrennt, entfernt oder ersetzt werden muss.
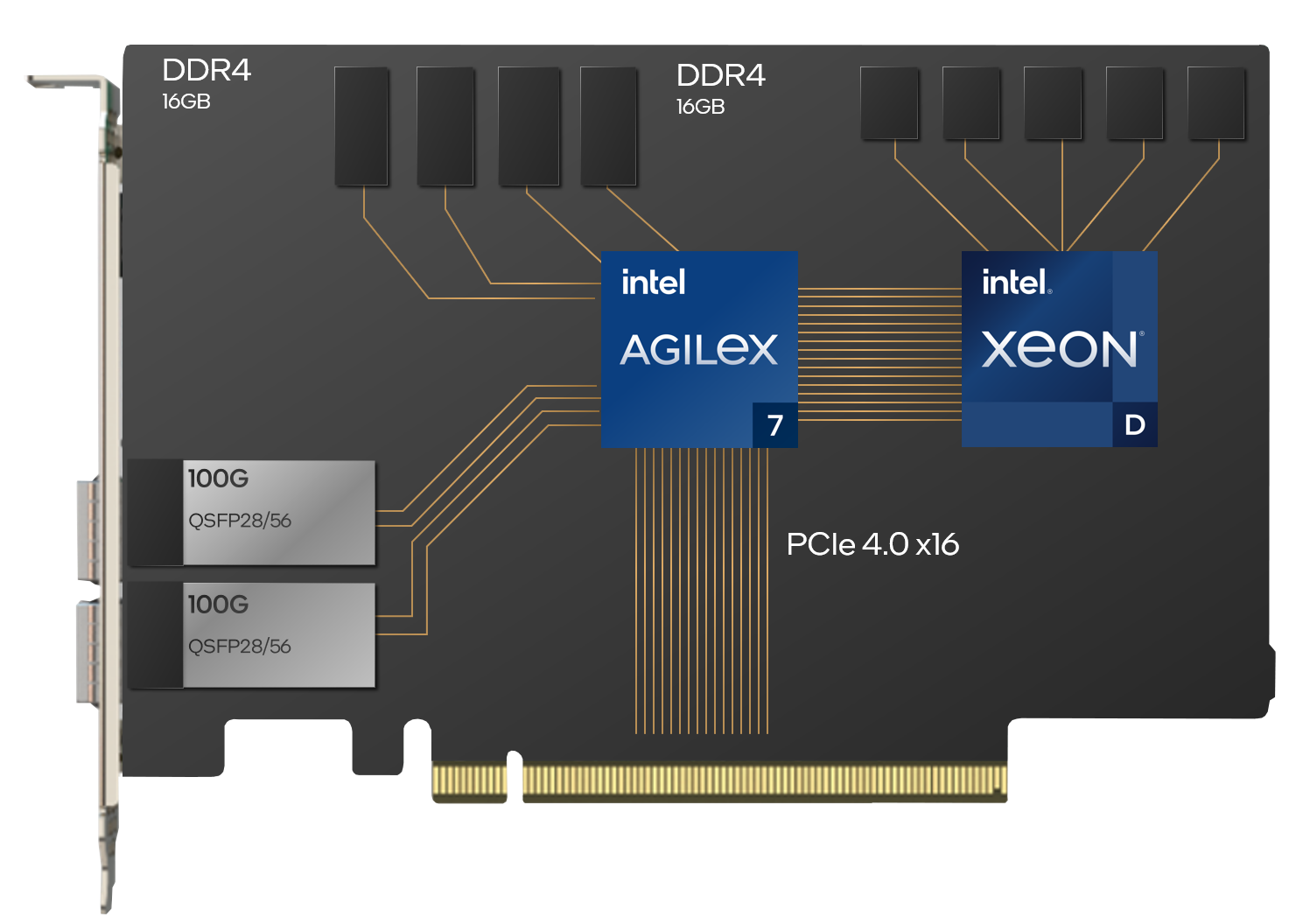
Napatech F2070X IPU
Die auf der Intel® IPU-Plattform F2000X-PL basierende Napatech F2070X IPU ist eine 2x100G-PCIe-Karte mit einem Intel Agilex® 7 FPGA der F-Reihe und einem Intel® Xeon® D Prozessor in einem FHHL-Formfaktor mit zwei Steckplätzen.
Die Standardkonfiguration der F2070X IPU umfasst einen Intel Agilex® 7 FPGA AGF023 mit vier Bänken an 4-GB-DDR4-Speicher und einen 2,3-GHz-Intel® Xeon® D-1736 Prozessor mit zwei Bänken an 8-GB-DDR4-Speicher. Zur Unterstützung bestimmter Workloads können andere Konfigurationsoptionen bereitgestellt werden.
Die F2070X IPU verbindet sich mit dem Host über eine PCIe 4.0-x16 (16 GTps)-Schnittstelle, mit einer zusätzlichen PCIe 4.0-x16 (16 GTps)-Schnittstelle zwischen dem FPGA und dem Prozessor.
Zwei QSFP28/56-Netzwerkschnittstellen auf der Vorderseite unterstützen Netzwerkkonfigurationen mit:
- 2x 100G;
-
8x 10G oder 8x 25G (mit Breakout-Kabeln).
Ein dedizierter PTP RJ45-Port bietet optionale Zeitsynchronisation mit einem externen SMA-F- und einem internen MCX-F-Stecker. IEEE 1588v2-Zeitstempel werden unterstützt.
Ein dedizierter RJ45 Ethernet-Stecker ermöglicht die Board-Verwaltung. Sichere FPGA-Image-Updates ermöglichen nach der Bereitstellung der IPU das Hinzufügen neuer Funktionen bzw. das Aktualisieren vorhandener Funktionen.
Auf dem Prozessor wird Fedora Linux mit einem UEFI-BIOS, PXE-Boot-Support, vollem Shell-Zugriff über SSH und UART ausgeführt.