Introduction
Since Hyperscan is a performance-oriented regular expression engine, we are often asked for comparisons against other regular expression libraries on a variety of different metrics. This post is a walkthrough of an experiment to compare Hyperscan’s performance against that of Google’s RE2 library when scanning for sets of patterns, as is done in many network security systems.
Scanning for Regex Sets
One of Hyperscan’s core features is its ability to scan efficiently for sets of regular expressions, compiling them all into an optimized database designed to scan for them all simultaneously.
When the regex set is compiled, the user provides an ID for each regex which is used to identify it when a match is found at scan time. For example, consider these three patterns:
100:/^(GET|POST|PUT|HEAD)/ 200:/index/ 300:/HTTP\/\d+\.\d+/
When the corpus “GET /index.php HTTP/1.1” is scanned against this set, Hyperscan will report a match for ID 100 at offset 3, ID 200 at offset 10 and ID 300 at offset 23. Unless told otherwise (with the HS_FLAG_SINGLEMATCH flag, or by asking Hyperscan to stop returning matches via the callback return value), Hyperscan will report all matches for a given ID – for example, scanning “index index index” will return three matches for ID 200 in this case.
Few open source regex engines provide support for efficiently matching multiple regular expressions in one pass, which makes performance comparisons for this usage difficult. Google’s RE2 matcher, however, does provide such a mode: their RE2::Set interface (C++ API header). Hyperscan and RE2 have different designs, each with their own engineering trade-offs, but it is useful to run comparative performance measurements to highlight those differences.
Experimental Design
To measure RE2::Set’s performance in the same context as Hyperscan, we built a modified version of the hsbench tool described in the Performance Analysis of Hyperscan with hsbench article, that is able to drive RE2::Set as well as Hyperscan, using the same pattern sets and corpora.
We used the snort_pcres regex set (all of which are supported by Hyperscan) as a starting point and removed a small number of patterns that were rejected by the RE2 parser for syntax differences or large repeat quantifiers. For example, RE2 rejects the pattern “/(Context|Action)\x3D[^\x26\x3b]{1024}/i” as it considers the repetition quantifier “{1024}” too large.
We ran a script that generated 20 random subsets of size N from these patterns for each N in 1..100 and collected a performance measurement from Hyperscan and from RE2::Set for each subset. Each data point is the maximum of five scans conducted with the same matcher and input corpus in order to minimize jitter and reduce any transient effects on performance. There is an RE2-specific issue here in particular: since RE2 builds its DFA state cache lazily, this avoids penalizing RE2 for the cost of initial state construction and ensures that a peak performance measurement is considered. In real-world use, such a startup cost may be more important.
RE2 allows a maximum memory limit to be set, with a default value of 8MB. If the memory limit is reached, RE2 flushes its cache of DFA states and begins again or (if this happens too often) falls back to NFA execution. We ran three tests to gauge the effect of changing this limit: the first with the default max_mem of 8MB, the second with max_mem set to 200MB, and the third with max_mem set to its maximum value of INT_MAX (2GB).
Results
The following is a scatter plot of throughput (in megabits/sec) against the size of the regex set, for regular expressions randomly chosen from the snort_pcres sample set and the alexa200.db web traffic sample corpus. The measurements were taken on a single core of an Intel Core i7-6700K CPU at 4.0 GHz.
We found that the best performance from RE2::Set was achieved with the INT_MAX setting for max_mem, so that’s what we show in this plot. Note that the y-axis (throughput in megabits/sec) is presented on a logarithmic scale.
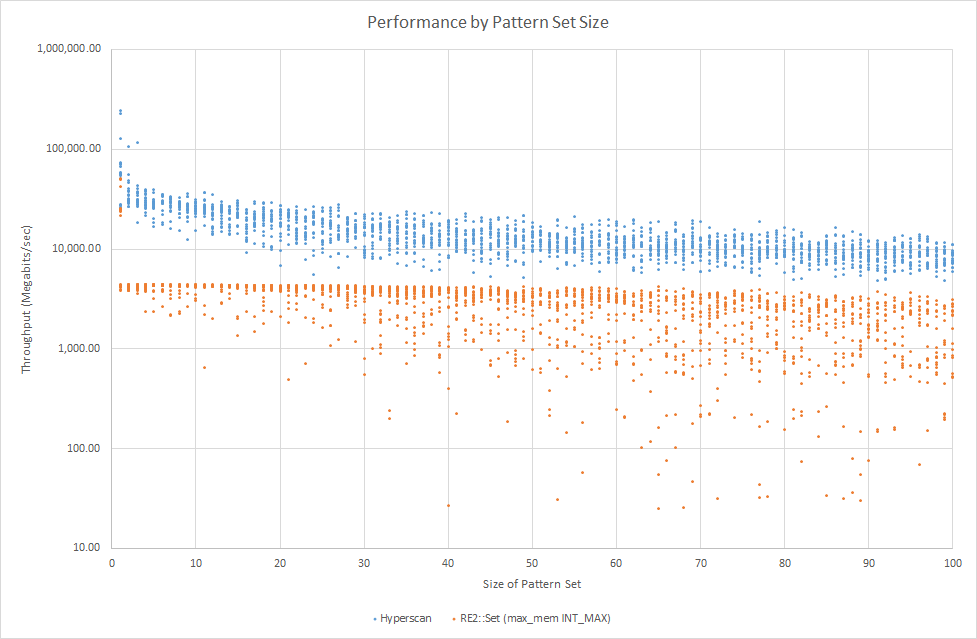
Two other data sets are of interest here, as well. To limit the time needed for data collection, we enforced a timeout of 300 seconds for each job, a limit which was occasionally triggered by the RE2::Set jobs. We also recorded peak memory usage after each job, as a guide to the memory required at scan time by RE2::Set for building its DFA cache.

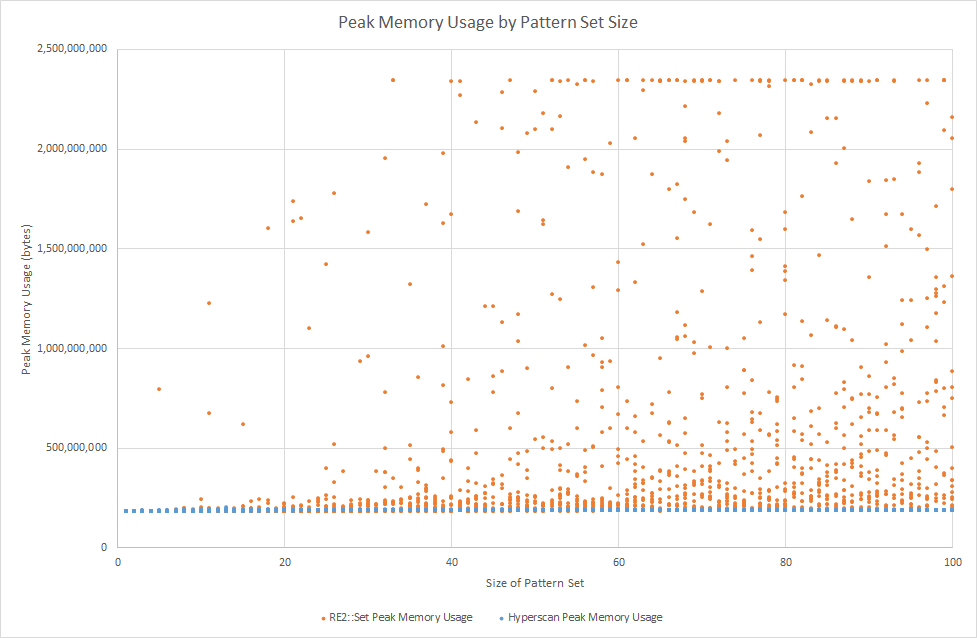
There are a number of conclusions we can draw from this performance comparison.
Firstly, Hyperscan offers a performance advantage for sets of patterns drawn from the snort_pcres regex set against web traffic. RE2::Set offers comparable performance for some single regex patterns, but drops to running at its baseline performance of 3.5-4.5 Gbps for sets larger than one pattern.
As the regex set size increases, RE2::Set requires more memory to build out its DFA state cache as it scans, and as such, its average-case performance begins to degrade. From the peak memory usage chart, we can see that even for fairly small sets (~ 30 patterns), peak memory usage for RE2::Set quickly approaches the maximum value of 2GB, with a corresponding effect on performance. This performance cost can be attributed to time spent flushing and rebuilding the cache, as well as the overhead of memory allocation at scan time. Note that the memory usage floor at ~ 180 MB is due to the memory required to hold the traffic corpus being scanned.
The chart of timeouts shows the number of cases that ran slowly enough to fail to complete within 300 seconds, which corresponds to a throughput result of about 5 Mbps in performance terms for this corpus. We can see from the chart that once we reach a pattern set size of 100 patterns, 9 of the 20 RE2::Set tests are timing out.
In comparison, Hyperscan offers high performance across the full range of pattern set sizes tested here, degrading gracefully as the pattern set size increases. What little variation there is in Hyperscan’s peak memory usage is attributable to the Hyperscan compiler. In block mode operation, Hyperscan performs no memory allocation at all in its scan path once a fixed-size scratch region has been pre-allocated.
Race to Crossover
Another way to compare Hyperscan with RE2::Set is in terms of performance including compile time, for use-cases where the pattern set is not known a priori. For typical cases, Hyperscan is faster at scanning data than RE2::Set (as shown in the results of the previous section), but it takes longer to compile a given pattern set (as it must completely construct its scanning database). Thus, we can determine the number of scanned bytes it takes for Hyperscan to “catch up” with RE2::Set for a given case when compile time is included.
To gather this data, we extended the benchmarking tool used for the previous experiment to run only one scan of the corpus, recording the time taken for pattern set compilation and the time taken to scan each block of data in the input.
We ran ten trials each for pattern set sizes of 10, 50, 100 and 200 patterns, and the table and chart below shows the crossover point for each trial. That is, the number of bytes scanned at which Hyperscan overtakes RE2::Set. This is the size of the task for which Hyperscan will be faster than RE2::Set even when compilation time is included. In all cases, the max_mem parameter for RE2 was set to INT_MAX.
| Trial | 10 Patterns | 50 Patterns | 100 Patterns | 200 Patterns |
| 1 | 165,971 | 40,460 | 5,289 | 21,644 |
| 2 | 93,971 | 3,563 | 24,953 | 34,620 |
| 3 | 111,251 | 76,691 | 21,644 | 20,974 |
| 4 | 134,291 | 33,713 | 29,333 | 30,793 |
| 5 | 237,971 | 16,654 | 23,493 | 13,774 |
| 6 | 44,840 | 54,939 | 16,654 | 5,993 |
| 7 | 201,971 | 43,380 | 59,431 | 6,625 |
| 8 | 33,713 | 57,264 | 13,774 | 13,774 |
| 9 | 267,668 | 76,691 | 57,264 | 13,774 |
| 10 | 96,851 | 56,549 | 33,713 | 16,654 |
| Mean | 138,850 | 45,990 | 28,555 | 17,863 |
The results show much variation. This is unsurprising given the variation in pattern sets: both regex engines will perform different work at compile time and scan at different rates depending on the pattern set being used. However, we can identify some trends.
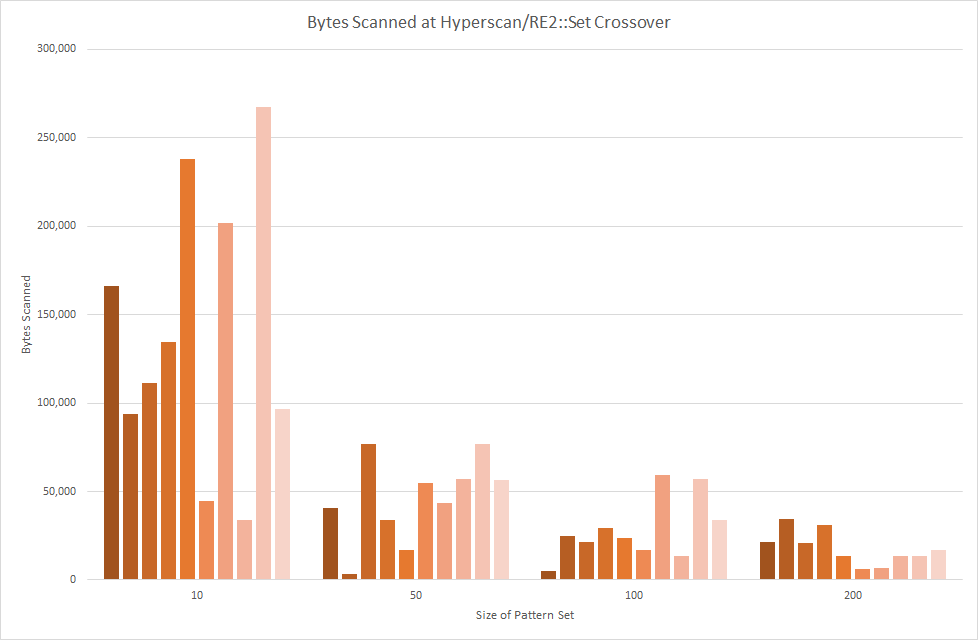
For the smallest cases tested, sets of ten patterns, Hyperscan overtakes RE2::Set after a few hundred KB of data scanned: the mean for this pattern set size is 139KB. As the number of patterns increases, the crossover point reduces, until for 200 patterns, we see a mean of 18KB with less variability in the inpidual samples.
From this data, we conclude that even if the set of patterns being scanned for is not known in advance (i.e. they cannot be compiled ahead of time), there is an advantage to using Hyperscan over RE2::Set if the data being scanned is more than a few hundred kilobytes in size.
Conversely, if both the number of patterns and the size of the data to be scanned is small – such as in use-cases like field validation or small filtration tasks – the fact that RE2::Set can compile its initial program and start scanning immediately gives it the advantage. In such cases, compilation of the pattern database dominates the total run time for Hyperscan.
(The results of this particular experiment have led us to investigate and improve Hyperscan’s compilation time on pattern sets in this size range, and we expect to make further improvements in future releases.)
Other Differences Between Hyperscan and RE2::Set
So far, we have focused on a performance comparison between Hyperscan and RE2::Set on a common, comparable use-case: determining which of a set of patterns match against a single contiguous block of data. However, as we said in the introduction, Hyperscan and RE2 are very different regex engines which have made different engineering tradeoffs, and it is worth discussing some of these as well.
RE2’s author, Russ Cox, goes into detail on the RE2 design in his blog post, Regular Expression Matching in the Wild. Essentially, RE2 parses a pattern, compiling it into a Thompson NFA, and then executes the NFA at scan time using a simulation that builds and caches the equivalent DFA states on the fly. As a result, the initial compilation stage in RE2 is very quick: it is simply parsing and NFA construction. DFA construction is deferred until scan time and performed lazily, limited to those states that are explored as the engine runs. (As we have seen, for the larger cases we tested against Web traffic, this can result in a very large number of states.)
Hyperscan does all of its compilation up front and uses the resultant immutable pattern database at scan time. Compilation for Hyperscan is complex: patterns are parsed and compiled into Glushkov NFAs (an alternate NFA construction that predates Thompson’s NFA and lacks epsilon transitions), and a variety of analyses and optimization passes are run to decompose the pattern into sub-components and literal fragments. These are combined into a set of communicating sub-engines that can have a variety of implementations (bitwise Glushkov NFA simulation, several DFA implementations, literal matchers, etc.) depending on the pattern’s requirements.
Both RE2 and Hyperscan are automata-based regex engines, meaning that they do not use backtracking matcher implementations, which is what causes regex engines like those used by Perl and PCRE to have exponential time worst-case complexity. The libraries support similar pattern syntax; Hyperscan follows PCRE pattern syntax exactly (although does not implement all the constructs and will fail with an error for unsupported constructs) while RE2 makes some variations to PCRE pattern syntax.
RE2::Set provides a multi-pattern interface to RE2, but provides only the ability to determine which patterns matched during a scan. Hyperscan provides the identity and offset of each match, including (if desired) for repeated matches of the same pattern during the scan.
A desirable property for many applications, especially in network security, is the ability to perform ‘streaming’ or ‘cross-packet’ inspection without requiring the library users to retain old data. Hyperscan offers the ability to scan in ‘streaming’ mode, where stream writes are written sequentially to a logical stream and regular expression matches are detected that cross stream write boundaries. This requires the ability to save a fixed ‘stream state’; Hyperscan’s stream state is sized based on the pattern inputs only. The capability to stream could be retrofitted to RE2 but is not currently possible with RE2.
RE2 is written entirely in C++ and requires that memory allocation take place in the scan path for building its DFA state cache (with a tunable memory bound, the max_mem parameter described earlier). In comparison, Hyperscan has a separable C++ compiler front-end and a C runtime for scanning, and performs no memory allocations at runtime beyond the allocation of fixed-size scratch space and (in streaming mode) stream state.
Hyperscan requires a modern x86 processor with at least Supplemental Streaming SIMD Extensions 3 (SSSE3) support and makes heavy use of features available on modern Intel processors for performance reasons. RE2 provides wider platform support.
Conclusion
We have illustrated a comparison between RE2::Set and Hyperscan where Hyperscan runs considerably faster, from an average of 5x for small pattern sets, and an even greater multiple as the pattern set size increases. Hyperscan also consumes less memory and has more predictable memory utilisation while scanning. Where the lifetime of the pattern is sufficiently large, Hyperscan’s additional compile time optimizations and compile-ahead model pays for itself.
RE2 and Hyperscan serve different niches in the regular expression space, and by no means exhaust the possibilities – neither system has the rich semantics of back-tracking engines, for example. We hope that this post illustrates some of the consequences of the different decisions we made in the design and implementation of Hyperscan.
Disclaimer
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Performance varies by use, configuration and other factors. Learn more on the Performance Index site.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Notice Revision #20110804